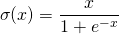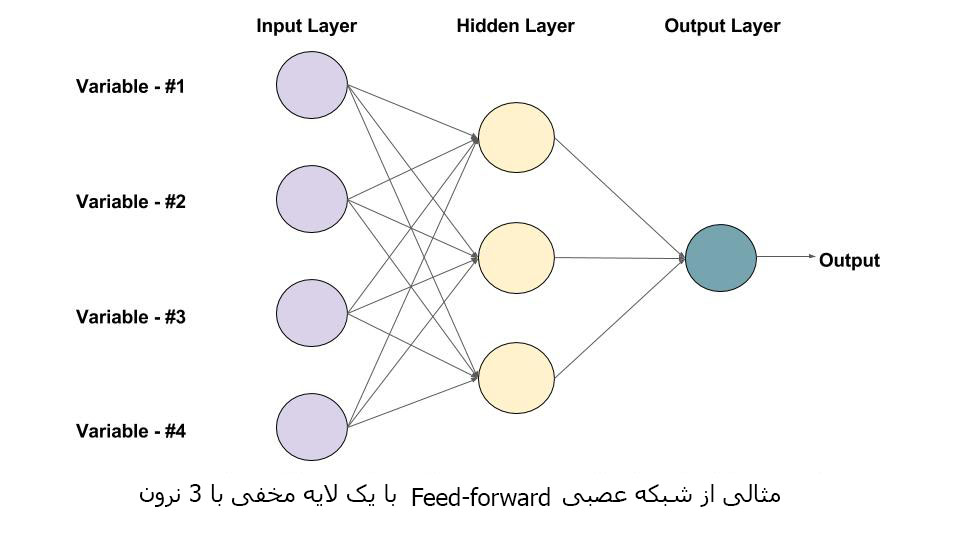
در این آموزش، اصول اولیه شبکه های عصبی Convolutional (CNNs) و نحوه استفاده از آنها برای یک کارکرد طبقه بندی تصویر را یاد خواهید گرفت. ما همچنین خواهیم دید که افزایش داده ها در بهبود عملکرد شبکه کمک می کند. ما در مورد آموزش پیشین درباره شبکه های عصبی Feedforward، توابع فعال سازی و مبانی Keras بحث کردیم. ما از مجموعه داده های MNIST و CIFAR10 برای توضیح مفاهیم مختلف استفاده خواهیم کرد.
1. انگیزه
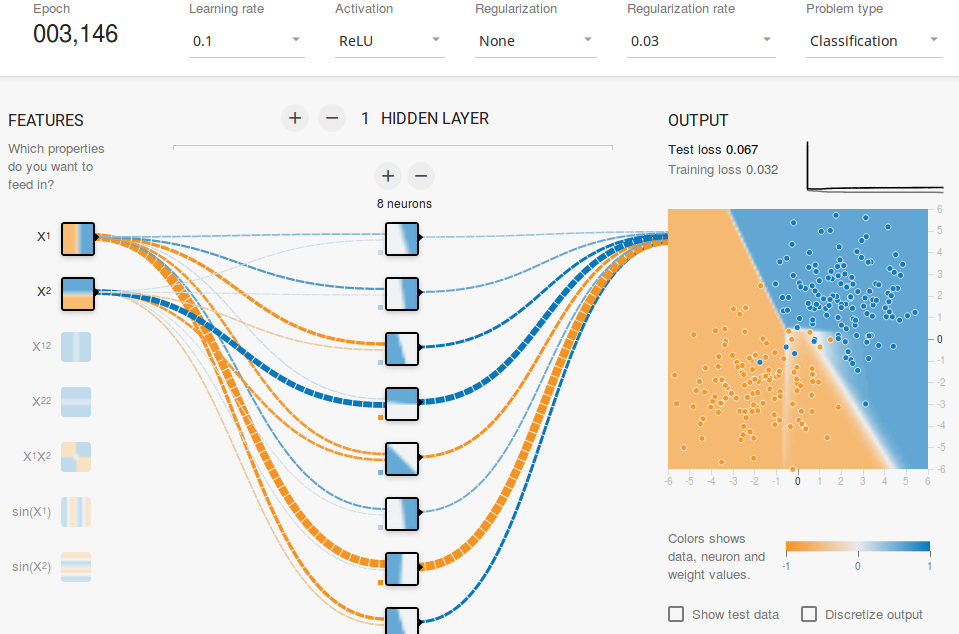
در مقاله قبلی ما در مورد طبقه بندی تصویر، ما از Perceptron Multilayer در مجموعه داده های ارقام MNIST استفاده کردیم. عملکرد بسیار خوب بود، به طوری که ما به دقت 98.3٪ در داده های آزمون دست یافتیم. اما این رویکرد مشکل داشت. در مجموعه داده های آموزشی ما، همه تصاویر در مرکز قرار دارند. اگر تصاویر در مجموعه آزمون خارج از مرکز قرار بگیرند، روش MLP با شکست مواجه می شود. ما می خواهیم شبکه ترجمه Invariant باشد.
با توجه به زیر یک مثال از شماره 7 است که به سمت چپ بالا و پایین سمت راست است. طبقه بندی کننده آن را به طور صحیح برای تصویر مرکزی پیش بینی می کند اما در دو مورد دیگر شکست می خورد. برای اینکه این کار را برای این تصاویر انجام دهیم یا باید MLP های جداگانه را برای مکان های مختلف آموزش دهیم یا باید اطمینان داشته باشیم که همه این تغییرات در مجموعه آموزش نیز وجود دارد، که من می توانم بگویم دشوار است یا نه غیر ممکن است.
شبکه کاملا متصل به تلاش برای یادگیری ویژگی ها یا الگوهای جهانی است. این به عنوان یک طبقه بندی خوب عمل می کند.
یکی دیگر از مشکلات عمده با یک طبقه بندی کامل متصل شده این است که تعداد پارامترها بسیار سریع افزایش می یابد، زیرا هر گره در لایه L به یک گره در L-1 متصل است. بنابراین شبکه های بسیار عمیق را تنها با استفاده از یک ساختار MLP امکان پذیر نمی سازد.
هر دو مشكل فوق به وسيله استفاده از شبكه عصبي Convolutional كه در بخش بعدي آن را مشاهده مي كنيم، تا حد زيادي حل مي شوند. ما در ابتدا مفاهیم درگیر در یک شبکه عصبی Convolutional را به طور مختصر توضیح خواهیم داد و سپس پیاده سازی CNN را در Keras مشاهده خواهیم کرد تا تجربهی دستوری داشته باشید.
2. شبکه عصبی Convolutional
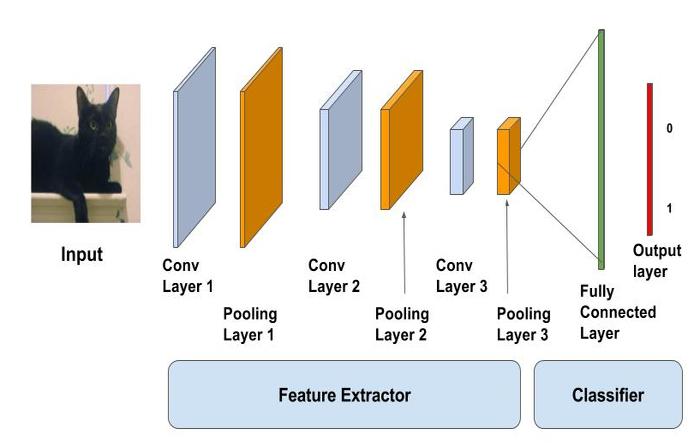
شبکه های عصبی انعقادی یک شکل از شبکه عصبی Feedforward هستند. با توجه به زیر یک طرح از یک CNN معمولی است. بخش اول شامل لایه های Convolutional و Max-pooling است که به عنوان ویژگی استخراج عمل می کنند. بخش دوم شامل لایه کامل متصل شده است که تحولات غیر خطی از ویژگی های استخراج را انجام می دهد و به عنوان طبقه بندی عمل می کند.

در نمودار بالا، ورودی به شبکه های Conv، Pool و Lens انباشته شده تغذیه می شود. خروجی می تواند یک لایه softmax باشد که نشان می دهد آیا یک گربه یا چیزی دیگری وجود دارد. شما همچنین می توانید یک لایه سیگموئید داشته باشید تا احتمال اینکه تصویر یک گربه باشد را به شما نشان دهد. بگذارید دو لایه را در جزئیات ببینیم.
2.1 لایه متخلخل
لنور کانولوشن را می توان به عنوان چشمان CNN در نظر گرفت. نورونهای این لایه به ویژگی های خاصی نگاه می کنند. اگر آنها ویژگی های مورد نظر خود را پیدا کنند، آنها فعال سازی بالا را تولید می کنند.
انقباض را می توان به عنوان یک مجموع وزنی بین دو سیگنال (از لحاظ اصطلاحات پردازش سیگنال) یا توابع (از لحاظ ریاضیات) در نظر گرفت. در پردازش تصویر، برای محاسبه کانولوشن در یک مکان خاص (x، y)، قطعه اندازه k × k را از تصویر مرکزی در محل (x، y) استخراج می کنیم. سپس مقادیر را در این عنصر توسط عنصر chunk با فیلتر تبدیل (همچنین kx k اندازه) ضرب می کنیم و سپس همه آنها را برای بدست آوردن یک خروجی واحد اضافه می کنیم. خودشه! توجه داشته باشید که k به عنوان اندازه کرنل نامیده می شود.
یک مثال از عملیات کانولاسیون در ماتریس اندازه 5 × 5 با یک هسته اندازه 3 × 3 در زیر نشان داده شده است:
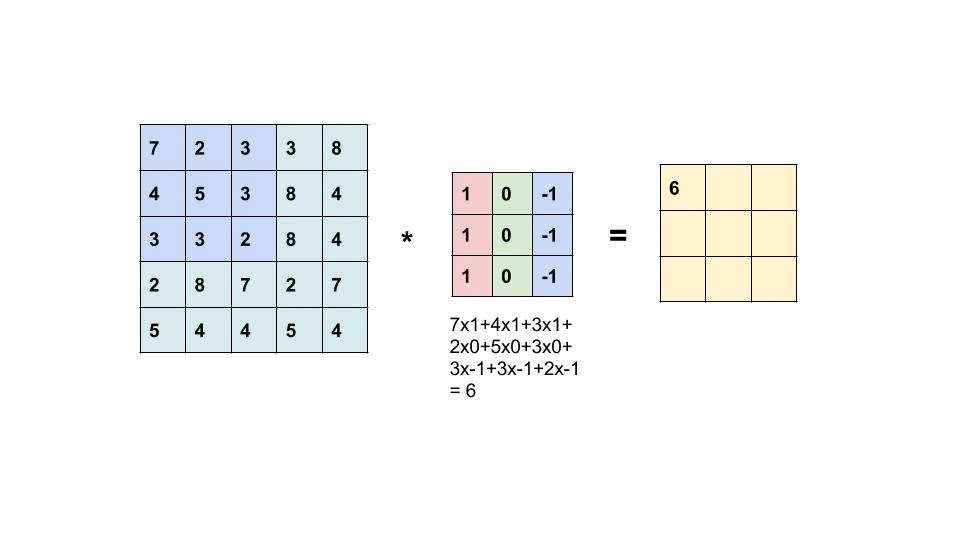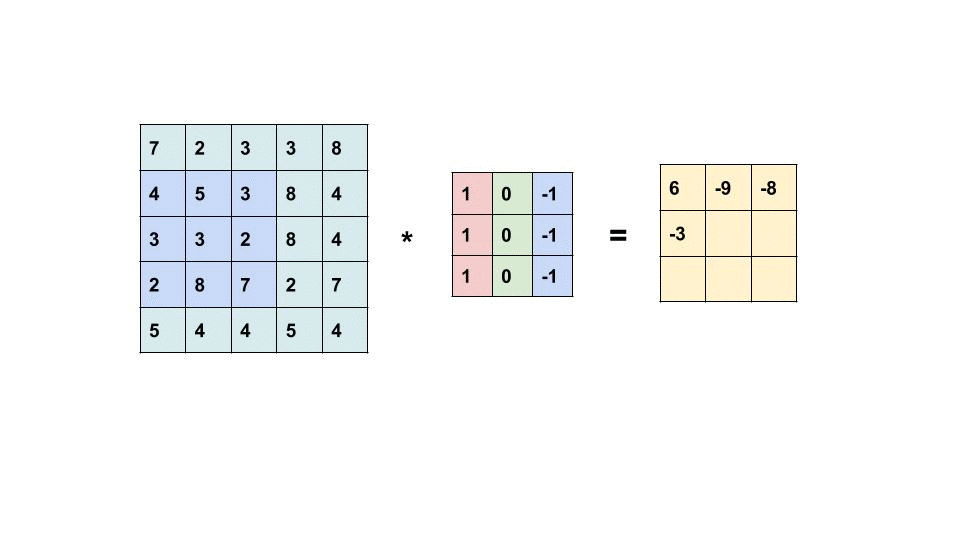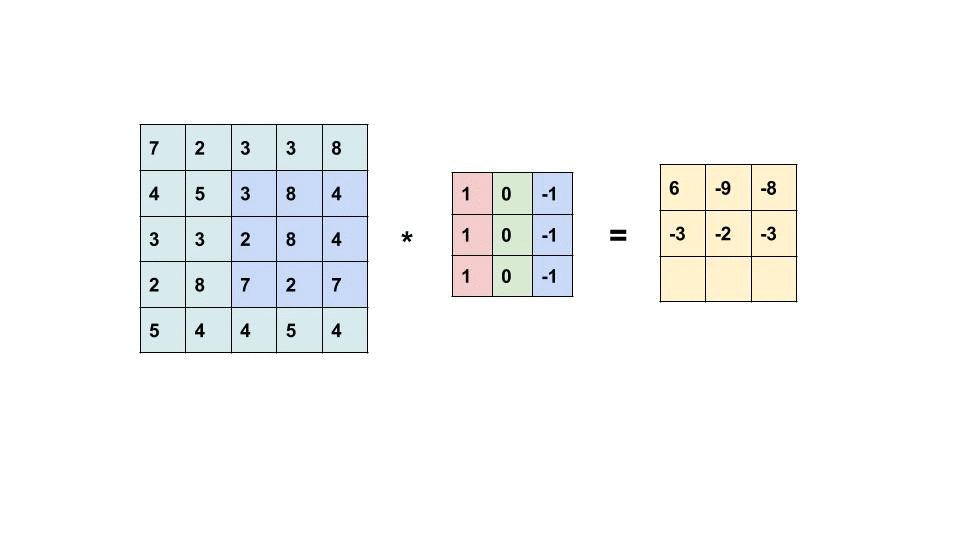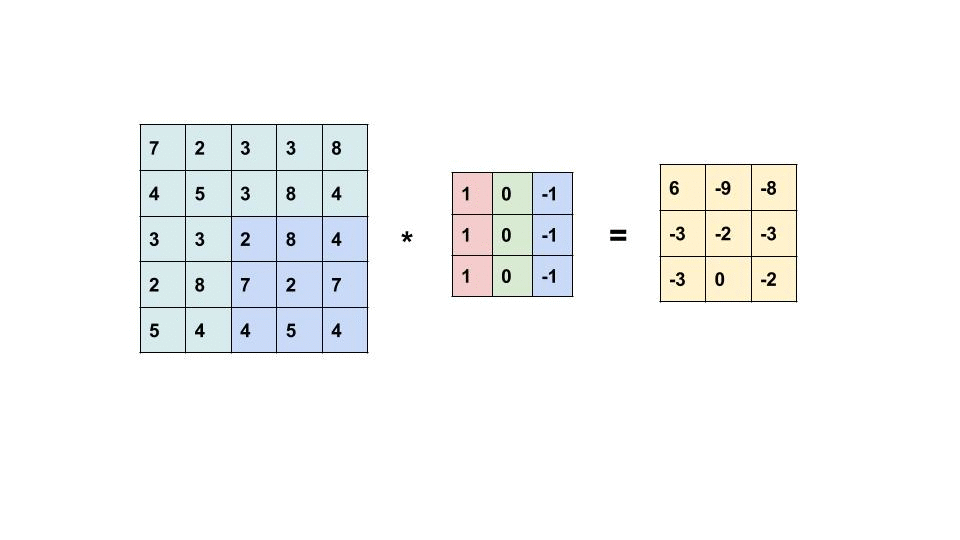
هسته کانولوشن در سراسر ماتریس اسلاید برای به دست آوردن یک نقشه فعال سازی است.
بیایید به مثال خاصی نگاه کنیم و شرایط را درک کنیم. فرض کنید تصویر ورودی 32x32x3 است. این چیزی جز آرایه ای از عمق 3 نیست. هر فیلتر کوانتومی که ما در این لایه تعریف می کنیم باید عمق یکسان با عمق ورودی باشد. بنابراین ما می توانیم فیلترهای کانولای عمق 3 را انتخاب کنیم (به عنوان مثال 3x3x3 یا 5x5x3 یا 7x7x3 و غیره). بیایید فیلترینگ کانورتور 3x3x3 را انتخاب کنیم. بنابراین، با اشاره به مثال فوق، در اینجا هسته کانولوشن به جای مربع یک مکعب خواهد بود.
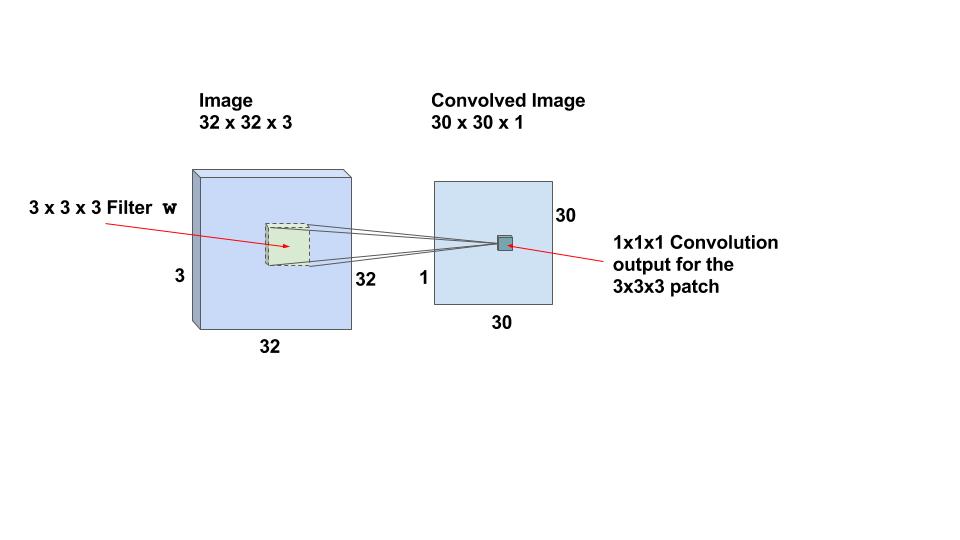
اگر ما می توانیم با استفاده از کشیدن فیلتر 3x3x3 بر روی کل تصویر اندازه 32x32x3، عملیات کانولو را انجام دهیم، یک تصویر خروجی از اندازه 30x30x1 به دست می آوریم. این به این دلیل است که عملیات convolution برای یک نوار 2 پیکسل در اطراف تصویر تعریف نشده است. ما باید اطمینان حاصل کنیم که فیلتر همیشه در داخل تصویر است. بنابراین 1 پیکسل از سمت چپ، راست، بالا و پایین تصویر دور می شود.
برای پیدا کردن ویژگی های مربوطه فیلترهای مشابه بر روی کل تصویر اسلاید شده اند. این باعث می شود CNNs ترجمه غریزی.
2.1.1 نقشه های فعال سازی
برای یک تصویر ورودی 32x32x3 و اندازه فیلتر 3x3x3، ما 30x30x1 مکان دارد و نورون مربوط به هر مکان وجود دارد. سپس خروجی های 30x30x1 یا فعال سازی همه نورون ها نقشه های فعال سازی نامیده می شود. نقشه فعال سازی یک لایه به عنوان ورودی به لایه بعدی عمل می کند.
2.1.2 توزیع وزن و تعصب
در مثال ما 30 × 30 = 900 نورون وجود دارد زیرا مکان های بسیاری وجود دارد که در آن 3x3x3 فیلتر قابل استفاده است. برخلاف شبکه های عصبی سنتی که وزن و تعصب نورون ها مستقل از یکدیگر هستند، در مورد CNN ها، نورون های مربوط به یک فیلتر در یک لایه، یک وزن و تعصب مشابه دارند.
2.1.3 گام های بلند برداشتن
در مورد فوق، پنجره را با یک پیکسل در یک زمان اسکید کردیم. ما همچنین می توانیم پنجره را با بیش از 1 پیکسل اسلاید کنیم. این شماره گام نامیده می شود.
2.1.4 فیلترهای چندگانه
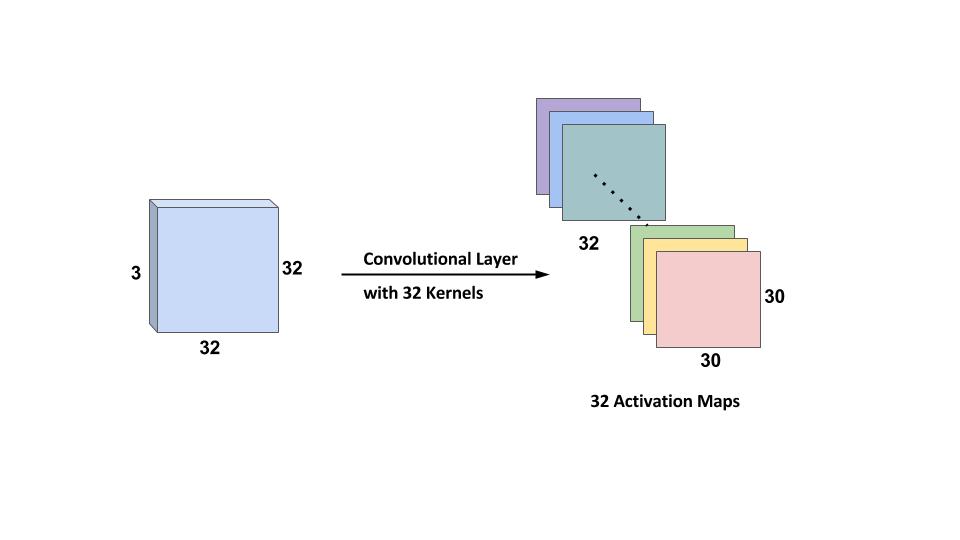
به طور معمول، ما در بیش از یک فیلتر در یک لایه کانوال استفاده می کنیم. اگر ما از 32 فیلتر استفاده کنیم، یک نقشه فعال سازی 30x30x32 اندازه خواهد داشت. لطفا برای یک نمای گرافیکی به شکل زیر مراجعه کنید.
توجه داشته باشید که تمام نورونهای مرتبط با یک فیلتر همان وزن و تعصب را دارند. بنابراین تعداد وزن ها در هنگام استفاده از 32 فیلتر به سادگی 3x3x3x32 = 288 است و تعداد بی توجهی ها 32 است.
نقشه های فعال سازی 32 به دست آمده از استفاده از هسته های محرک در زیر نشان داده شده است.
2.1.5 پوسته پوسته شدن
همانطور که می بینید، پس از هر کانولوشیم، خروجی کاهش می یابد (همانطور که در این مورد ما از 32 × 32 به 30 × 30 می رویم). برای راحتی، یک عمل استاندارد برای نوک پد به مرز لایه ورودی است به طوری که خروجی همان اندازه لایه ورودی است. بنابراین، در این مثال، اگر یک لایه از ابعاد 1 را در هر دو طرف لایه ورودی اضافه کنیم، اندازه لایه خروجی 32x32x32 خواهد بود که باعث سادهتر شدن اجرای آن می شود. بگذارید بگوییم شما دارای یک ورودی از اندازه NxN، یک فیلتر از اندازه F است و شما از stride S استفاده می کنید و یک عدد صفر از اندازه P به تصویر ورودی اضافه می شود. سپس، خروجی از اندازه MxM خواهد بود که در آن
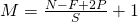
ما می توانیم الزامات مورد نیاز را محاسبه کنیم تا ابعاد ورودی و خروجی با تنظیم در معادله فوق و حل کردن P برای یکسان باشد.
2.2 CNN ها ویژگی های سلسله مراتبی را یاد می گیرند
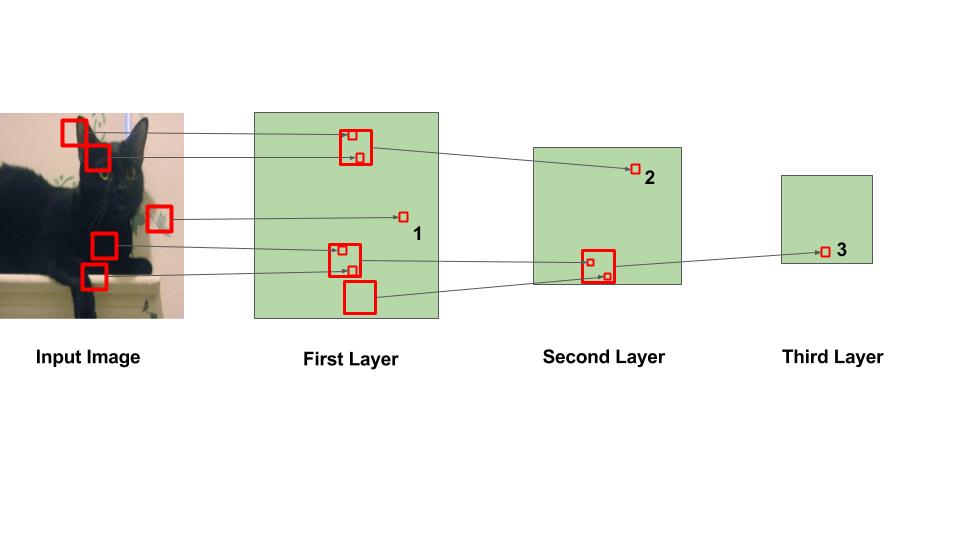
بیایید بحث کنیم چگونه CNN ها ویژگی های سلسله مراتبی را یاد بگیرند.
در شکل بالا، مربع های بزرگ نشان دهنده منطقه ای است که عملیات کانولو انجام می شود و مربع های کوچک نشان دهنده خروجی عملیاتی است که فقط یک عدد است. مشاهدات زیر می بایست ذکر شود:
در لایه اول، مربع مشخص شده 1 از ناحیه ای در تصویر که در آن برگ رنگ می شود به دست می آید.
در لایه دوم، مربع مشخص شده 2 از مربع بزرگتر در لایه 1 بدست می آید. اعداد در این مربع از چندین ناحیه از تصویر ورودی به دست می آیند. به طور خاص، کل منطقه اطراف گوش چپ گربه مسئول ارزش در مربع مشخص شده 2 است.
به همین ترتیب، در لایه سوم، این اثر آبشار باعث می شود مربع مشخص شده 3 از یک منطقه بزرگ در اطراف منطقه پا به دست آید.
ما می توانیم از بالا بیان کنیم که لایه های اولیه به نقاط کوچکتر تصویر نگاه می کنند و بنابراین می توانند فقط ویژگی های ساده مانند لبه ها / گوشه ها و غیره را یاد بگیرند. همانطور که در عمق شبکه قرار می گیریم، نورون ها از قسمت های بزرگتر تصویر دریافت می کنند و از نورون های مختلف دیگر. بنابراین، نورونها در لایه های بعد می توانند ویژگی های پیچیده ای مانند چشم ها / پاها را یاد بگیرند و چه چیزی نمی کنند!
2.3 حداکثر لایه جمع آوری
لایه جمع کننده بلافاصله بعد از لایه کنوولاسیون برای کاهش اندازه فضایی (فقط عرض و ارتفاع، نه عمق) استفاده می شود. این تعداد پارامترها را کاهش می دهد، در نتیجه محاسبات کاهش می یابد. با استفاده از پارامترهای کمتر اجتناب از overfitting.
توجه: Overfitting شرایطی است که یک مدل آموزش دیده به خوبی بر روی داده های آموزشی کار می کند، اما به خوبی بر روی داده های آزمون کار نمی کند.
شایع ترین شکل جمع آوری حداکثر جمع شدن است که ما یک فیلتر اندازه p را می گیریم و حداکثر عملیات را بر قسمت اندازه تصویر اعمال می کنیم.
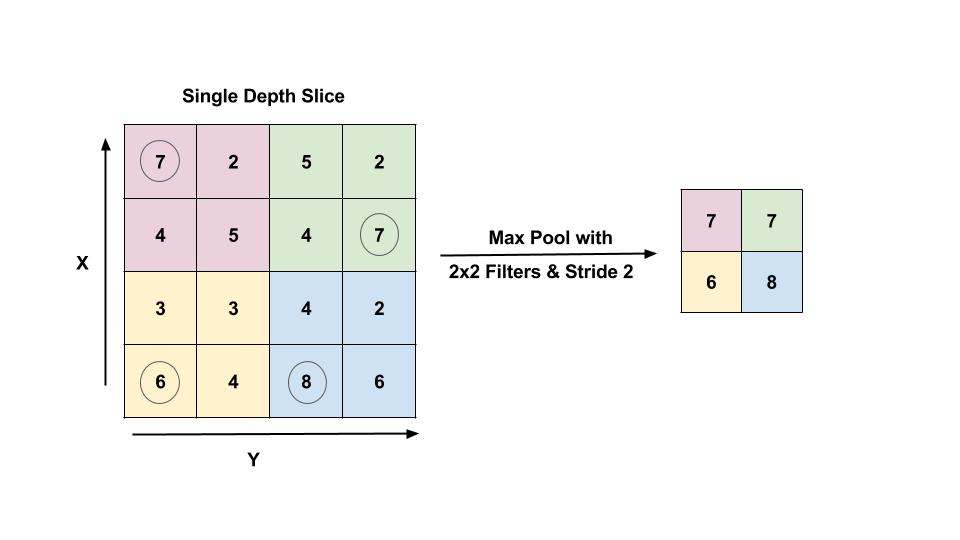
شکل: حداکثر لایه بالایی با اندازه فیلتر 2 × 2 و گام 2 نشان داده شده است. خروجی حداکثر مقدار یک منطقه 2 × 2 است که با استفاده از ارقام محاصره نشان داده شده است.
شایعترین عملیات تلفیقی با فیلتر اندازه 2 × 2 با گام 2 انجام می شود. این در واقع نصف مقدار ورودی را کاهش می دهد.
حالا بیایید از بحث نظری بگذریم و به اجرای یک CNN برویم.
3. اجرای CNN ها در Keras
3.1 مجموعه داده – CIFAR10
مجموعه داده CIFAR10 همراه با Keras همراه است. این 50،000 تصویر آموزشی و 10،000 تصویر تست دارد. 10 کلاس مانند هواپیما، ماشین، پرنده، گربه، گوزن، سگ، قورباغه، اسب، کشتی و کامیون وجود دارد. تصاویر 32 × 32 اندازه هستند. در زیر چند نمونه هستند.

3.2 شبکه
برای اجرای یک CNN، ما لایه های Convolutional را با هم ترکیب می کنیم و سپس لایه های Max Pooling را می سازیم. ما همچنین از Dropout برای جلوگیری از اضافه کردن استفاده می کنیم. در نهایت، ما یک لایه کاملا متصل (انبساطی) و یک لایه softmax اضافه می کنیم. در زیر ساختار مدل است.
در کد بالا، ما از 6 لایه کانولوشن و 1 لایه کامل متصل استفاده می کنیم. خطوط 6 و 7 لایه کانولوشن را با 32 فیلتر / هسته با اندازه پنجره 3 × 3 اضافه می کند. به طور مشابه، در خط 10، یک لایه متنی با 64 فیلتر اضافه می کنیم. در خط 8، یک لایه حداکثر جمع کننده با اندازه پنجره 2 × 2 اضافه می کنیم. در خط 9، یک لایه رها کردن را با نسبت 0.2 به خروجی اضافه می کنیم. در خطوط نهایی ما لایه متراکمی را اضافه می کنیم که طبقه بندی را در میان 10 کلاس با استفاده از یک لایه softmax انجام می دهد.
اگر ما خلاصه مدل را بررسی کنیم می توانیم اشکال هر لایه را ببینیم.

این نشان می دهد که از آنجا که ما در لایه اول استفاده کرده ایم، شکل خروجی همانند ورودی است (32 × 32). اما لایه دوم دوم با دو پیکسل در هر دو ابعاد کوچک می شود. همچنین اندازه خروجی بعد از لایه pooling به دلیل اینکه از یک گام 2 و یک پنجره 2 × 2 استفاده کردیم، نصف شده است. لایه نهایی droupout دارای خروجی 2x2x64 است. این باید به آرایه تک تبدیل شود. این کار توسط لایه مسطح انجام می شود که آرایه 3D را به آرایه 1D از اندازه 2x2x64 = 256 تبدیل می کند. لایه نهایی دارای 10 گره از آنجا که 10 کلاس وجود دارد.
3.3. آموزش شبکه
برای آموزش شبکه، ما از گردش ساده ساده create -> compile -> fit در اینجا توضیح خواهیم داد. از آنجایی که این یک مشکل طبقه بندی 10 طبقه است، از یک قطعه انتروپی متقاطع متقارن استفاده می کنیم و از RMSProp بهینه ساز برای آموزش شبکه استفاده می کنیم. ما آن را برای چندین دوره اجرا خواهیم کرد. در اینجا ما آن را برای 100 دوره اجرا می کنیم.
3.4. افت و خطای دقیق
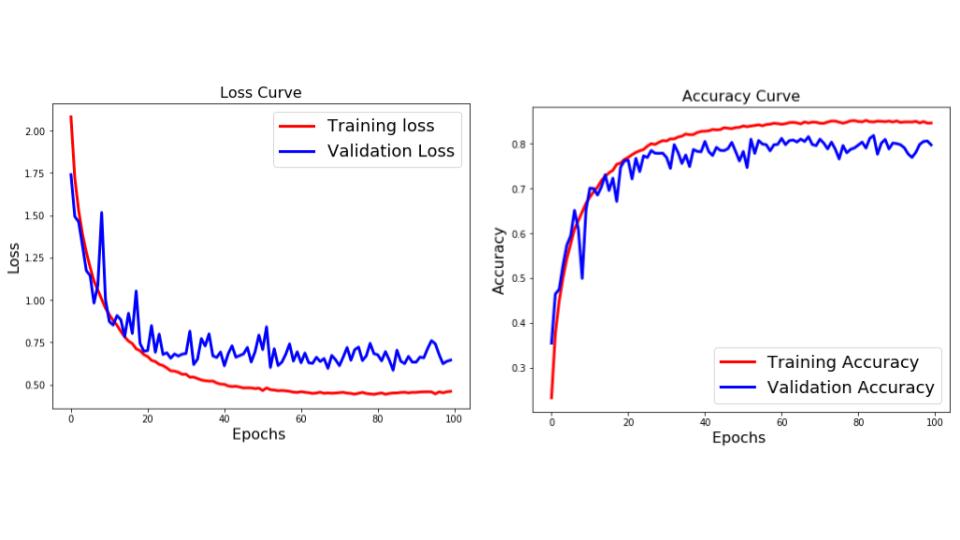
با توجه به زیر، منحنی های از دست دادن و دقت هستند.
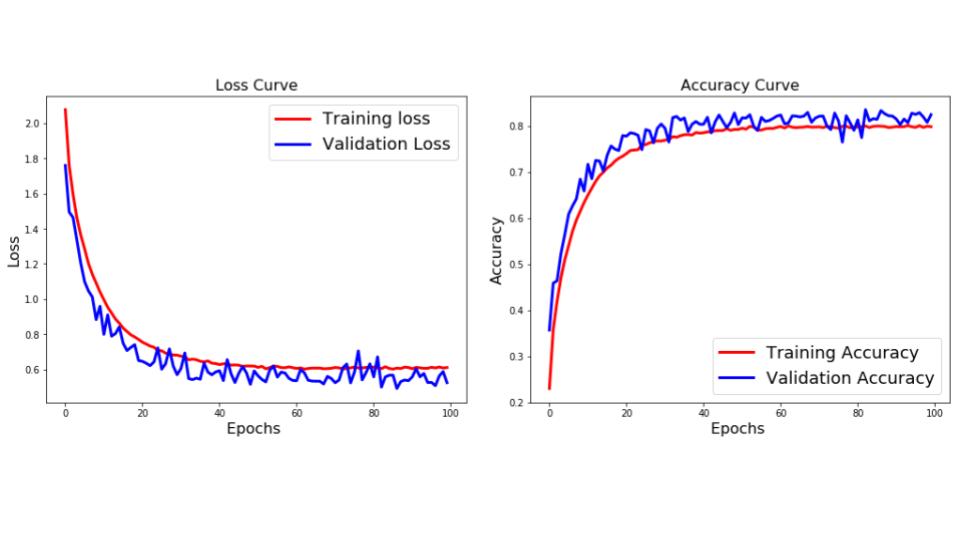
از منحنی های بالا می توان دید که تفاوت بین آموزش و اعتبار سنجی از بین رفته است. این نشان می دهد که شبکه سعی کرده است داده های آموزشی را حفظ کند و بنابراین می تواند دقت بیشتری در مورد آن داشته باشد. این نشانه ای از Overfitting است. اما ما قبلا از Dropout در شبکه استفاده کرده ایم، پس چرا هنوز آن را بیش از حد تعریف می کنیم؟ بگذارید ببینیم آیا ما می توانیم با استفاده از چیز دیگری بیش از حد برآورد کنیم.
4. با استفاده از افزایش داده ها
یکی از دلایل اصلی اضافه کردن این است که شما اطلاعات کافی برای آموزش شبکه خود ندارید. به غیر از تنظیم، یکی دیگر از روش های بسیار موثر برای مقابله با Overfitting، Data Augmentation است. این روند مصنوعی ایجاد تصاویر بیشتر از تصاویری است که شما در حال حاضر با تغییر اندازه، جهت گیری و غیره از تصویر است. این می تواند یک کار خسته کننده باشد، اما خوشبختانه، این را می توان در Keras با استفاده از مثال ImageDataGenerator انجام داد.
در کد بالا، ما برخی از عملیات را که می توان با استفاده از ImageDataGenerator برای افزایش اطلاعات انجام داد را ارائه می دهیم. این شامل چرخش تصویر، تغییر تصویر به سمت چپ / راست / بالا / پایین با مقدار، تلنگر تصویر به صورت افقی یا عمودی، برش یا زوم تصویر و غیره برای لیست کامل، مستندات را بررسی کنید. برخی از تصاویر تولید شده در زیر نشان داده شده است.

4.1 آموزش با افزایش اطلاعات
همانند بخش قبل، ما مدل را ایجاد خواهیم کرد، اما در هنگام آموزش از افزایش داده استفاده خواهیم کرد. ما از ImageDataGenerator برای ایجاد یک ژنراتور که شبکه را تغذیه خواهد کرد.
در کد بالا
ما ابتدا مدل را ایجاد و پیکربندی کردیم.
سپس یک شی ImageDataGenerator ایجاد می کنیم و آن را با استفاده از پارامترهای تلنگر افقی و ترجمه تصویر پیکربندی می کنیم.
تابع datagen.flow () پس از انجام تحولات / افزایش داده ها در طی اکتیو کردن ژنراتور داده ها، مجموعه داده ها را تولید می کند.
تابع fit_generator مدل را با استفاده از داده های به دست آمده در دسته از عملکرد datagen.flow آموزش می دهد.
4.2 افت و خطای دقیق
دقت آزمایش بیشتر از دقت آموزش است. این بدان معنی است که مدل به خوبی تعریف شده است. این بدان علت است که این مدل بر روی اطلاعات بسیار بدتر (به عنوان مثال – تصاویر تلنگر شده) آموزش داده شده است، بنابراین یافته های داده های نرمال را آسان تر برای طبقه بندی می کند.
5. چه بعدی؟
به نظر می رسد که پارامترهای زیادی برای انتخاب وجود دارد و پس از آن آموزش طول می کشد. ما نمی خواهیم با این دو مشکل در رابطه با مشکلات ساده مواجه شویم. بسیاری از محققانی که در این زمینه کار می کنند، بسیار سخاوتمندانه از مدل های آموزش دیده خود که به میلیون ها تصویر و صدها ساعت در بسیاری از پردازنده های گرافیکی آموزش داده شده اند، استفاده می کنند. ما می توانیم مدل های خود را اهرم بندی کنیم و سعی کنیم از مدل های آموزش یافته خود به عنوان نقطه شروع استفاده کنیم تا از ابتدا شروع کنیم. ما یاد بگیریم که چگونه در انتقال پست الکترونیکی خودمان به آموزش انتقال و تنظیم دقیق بپردازیم.